Abstract
Detecting unanswerable user queries remains essential for the reliable deployment of real-world embodied agents. However, modern vision-language models (VLMs) often generate overly confident answers even when the available visual memory cannot support the query. Such overconfidence carries different costs across tasks: the agent may give misleading information in Embodied Question Answering, or pick an arbitrary coordinate and physically guide the user there in spatial reasoning for navigation. Despite these stakes, only a few prior studies address when and how an embodied VLM should respond with “I do not know.”
We propose Semantic Flip, a simple and effective framework that synthesizes auxiliary OOD samples for embodied refusal without external OOD annotation. The key idea is to independently transform the query and the video memory to construct auxiliary OOD pairs that lack sufficient visual grounding. These synthesized pairs train a lightweight rejection module on top of a frozen pretrained VLM, and the module attaches to any existing VLM-based pipeline without retraining the underlying model. Across two complementary benchmarks, Semantic Flip consistently outperforms strong prompting baselines. We also introduce SpaceReject, a new refusal benchmark for spatial localization with deliberately unanswerable queries over long video memory, where Semantic Flip reaches an F1 of 0.9559. All experiments use only open-source models, so the full pipeline is reproducible.
Method
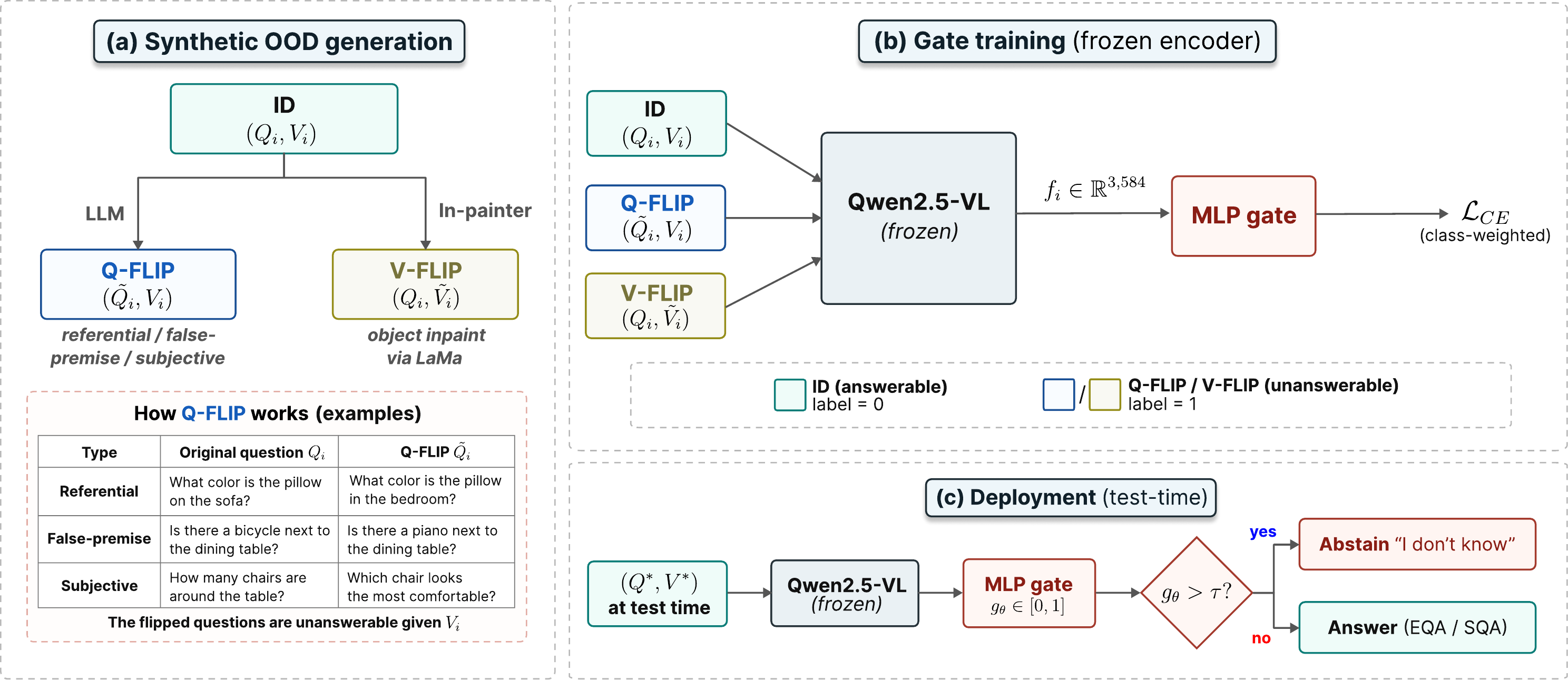
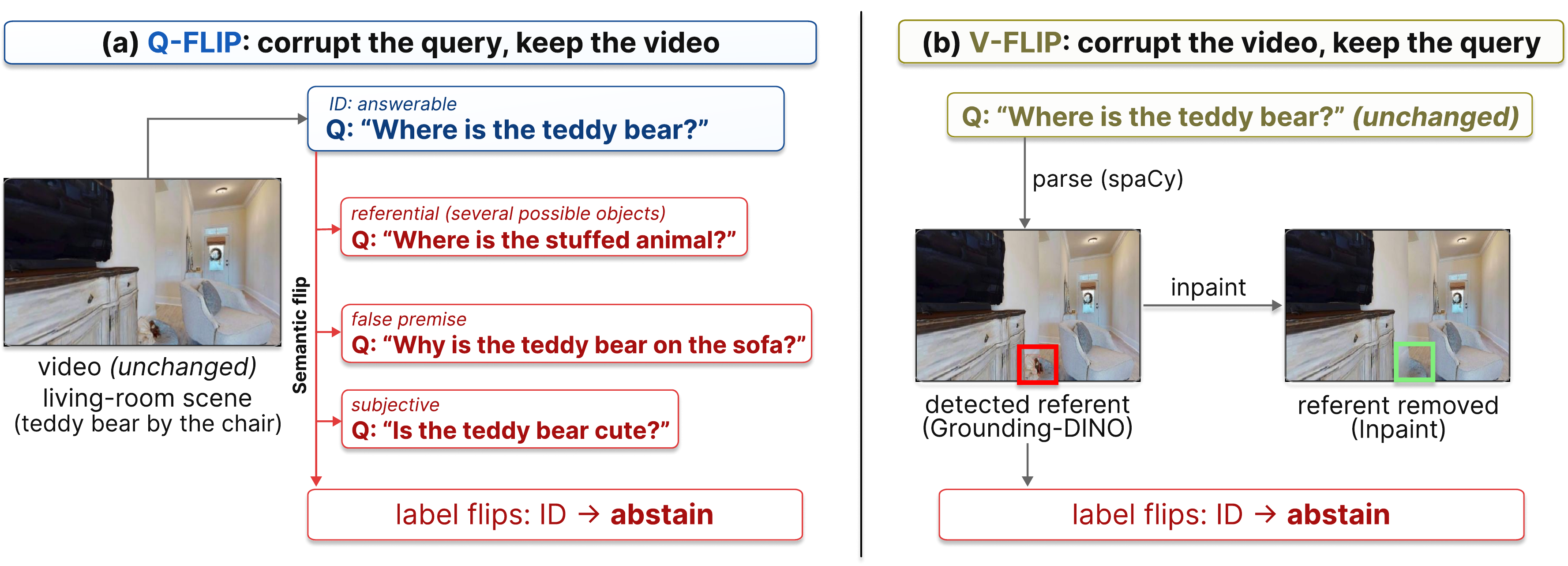
Semantic Flip builds two complementary OOD distributions from answerable training pairs by flipping exactly one side of an otherwise answerable pair.
Rewrite the question into an ungroundable variant while keeping the video memory unchanged.
Keep the question, but erase its referent from the memory through a parse → detect → inpaint pipeline (spaCy, Grounding-DINO, LaMa).
A frozen VLM encoder produces one joint embedding for the in-distribution, Q-Flip, and V-Flip samples, and only a small 3-layer MLP rejection gate is trained on top. Because the backbone stays frozen, the gate reuses the forward pass the agent already runs and adds essentially no extra inference cost.
Results
With a frozen 7B encoder and a small head, Semantic Flip outperforms strong prompting baselines on both tasks. It also generalizes to abstention categories never seen during synthesis, e.g. 0.89 OOD recall on Information Unavailability, a category Q-Flip does not target.
| Method | F1 | Bal. Acc | Recall | Spec. |
|---|---|---|---|---|
| Qwen2.5-VL-32B prompting (Coarse / Fine / CoT) | Coming soon | |||
| Semantic Flip (ours) | 0.7110 | 0.6684 | 0.8158 | 0.5211 |
| Method | BalAcc | F1 | Recall | Spec. |
|---|---|---|---|---|
| C2 (Tool), Qwen3-8B prompting | 0.8778 | 0.8874 | 0.9630 | 0.7926 |
| Semantic Flip, Q-Flip only | 0.9504 | 0.9494 | 0.9363 | 0.9644 |
| Semantic Flip, Q-Flip + V-Flip | 0.9563 | 0.9559 | 0.9467 | 0.9659 |
Full appendix tables (threshold sweep, fill-operator ablation, pool-size sweep, per-category recall, per-LLM baselines) are reproduced end to end by the reproduction notebook.
Get started
A single 48 GB GPU (e.g. RTX A6000) is enough for the whole pipeline. All checkpoints are public and pulled from the Hugging Face Hub on first use.
# set up the environment git clone https://github.com/ndb796/SemanticFlip.git cd SemanticFlip conda create -n semflip python=3.10 -y conda activate semflip pip install -r requirements.txt # reproduce every AbstainEQA result, top to bottom jupyter lab notebooks/reproduce.ipynb
Backbones are all open-source: Qwen2.5-VL-7B / 32B-AWQ, Qwen2.5-7B, and grounding-dino-tiny.
Dataset
The SpaceReject and SpaceRejectExtra queries, videos, annotations, and trained models will be released on Hugging Face.
huggingface.co/datasets/ndb796/SpaceReject.Citation
@article{na2026semanticflip,
title = {Semantic Flip: Synthetic OOD Generation for Robust Refusal
in Embodied Question Answering and Spatial Localization},
author = {Na, Dongbin and Kim, Chanwoo and Choi, Giyun and Hong, Dooyoung},
year = {2026}
}